

Near misses e acidentes em produtos digitais, no delivery e na operação

Desde inicio deste ano alguns aeroportos nos Estados Unidos protagonizaram situações extremamente perigosas onde quase aconteceram acidentes graves durante a decolagem, vôo ou pouso de aeronaves em solo americano.
Um dos mais emblemáticos envolveu uma aeronave da Southwest Airlines e outra da FedEx no aeroporto de Austin no Texas. O vídeo abaixo mostra uma simulação do que ocorreu, feita com a telemetria das aeronaves e da torre de controle e ilustra o desastre que quase aconteceu.
Por muito pouco uma aeronave não pousou literalmente “em cima” de outra que estava taxiando para decolar:
A FAA ( Federal Aviation Agency ) estipula critérios bastante rígidos e claros sobre o que constitui um acidente a ser investigado, sejam por conta de falha ou mal funcionamento dos controles de vôo, fogo a bordo, colisão durante vôo, decolagem ou pouso, falhas elétricas, danos estruturais as turbinas e outros.
Investigar acidentes parece algo um tanto natural, não apenas para responsabilizar os envolvidos da maneira devida, mas especialmente para gerar o aprendizado e feedback para a melhoria do sistema de forma a evitar que acidentes daquele tipo aconteçam novamente.
No entanto, a FAA também define de maneira bastante criteriosa o chamado Near Mid Air Collision (NMAC) onde são investigados incidentes de quase colisões que aconteceram durante um vôo, desde a decolagem até o seu pouso no destino.
A definição formal do NMAC é a seguinte:
A near midair collision is defined as an incident associated with the operation of an aircraft in which a possibility of collision occurs as a result of proximity of less than 500 feet to another aircraft, or a report is received from a pilot or a flight crew member stating that a collision hazard existed between two or more aircraft.
A ênfase aqui acontece no termo near ( quase ) ou na palavra possibility, o que pede a seguinte pergunta: Porque é tão importante ter rigor, controle e fazer investigações sobre os quase acidentes da mesma forma como quando acidentes de fato acontecem?
Acidentes não costumam acontecer de maneira isolada, assim como também não costumam acontecer sem antes dar alguns sinais claros de que um problema em potencial está por acontecer.
Acidentes, especialmente os grandes acidentes, costumam ser sistêmicos e evidenciam propriedades emergentes do conjunto de componentes envolvidos naquele sistema e as suas interações.
Por exemplo, se mudarmos da indústria aérea para a marítima, podemos estudar o naufrágio da embarcação MS Herald Free Enterprise na Bélgica.

fonte: MS Herald Free Enterprise - Wikipedia / Applying systems thinking to analyze and learn from events, Nancy Leveson
Foram diversos problemas sistêmicos que levaram ao desastre que aconteceu em 6 de março de 1987, onde o navio zarpou com o seu deck inferior aberto permitindo a entrada de agua no compartimento onde existiam passageiros e carros, causando o seu naufrágio e a morte de mais de 190 pessoas:
“(…) On the day the ferry capsized, the Herald of Free Enterprise was working the route between Dover and the Belgium port of Bruges-Zeebrugge. This was not her normal route and the linkspan at Zeebrugge had not been designed specifically for the Spirit class of vessels. The linkspan used spanned a single deck and so could not be used to load decks E and G simultaneously. The ramp could also not be raised high enough to meet the level of deck E due to the high spring tides being encountered at that time. This limitation was commonly known and was overcome by filling the forward ballast tanks to lower the ferry’s bow in the water. The Herald was due to be modified during its refit in 1987 to overcome this problem.
Before dropping moorings, it was normal practice for a member of the crew, the Assistant Bosun, to close the doors. The First Officer also remained on deck to ensure they were closed before returning to the wheel house. To keep on schedule, the First Officer returned to the wheel house before the ship dropped its moorings (which was common practice), leaving the closing of the doors to the Assistant Bosun, who had taken a short break after cleaning the car deck upon arrival at Zeebrugge. He had returned to his cabin and was still asleep when the ship left the dock. The captain could only assume that the doors had been closed because he could not see them from the wheel house due to their construction, and there were no indicator lights in the wheelhouse to show door position. There was confusion as to why no one else closed the doors. A few years earlier, one of the Herald’s sister ships sailed from Dover to Zeebrugge with the bow doors open, but she made it to the destination without incident. It was therefore believed that leaving the bow doors open should not alone have caused the ship to capsize.
Another factor that contributed to the capsizing was the depth of the water: if the ship’s speed had been below 18 knots (33 km/h) and the ship had not been in shallow water, people on the car deck would probably have had time to notice the bow doors were open and close them. But open bow doors were not alone enough to cause the final capsizing. Almost all ships are divided into watertight compartments below the water line so that in the event of flooding, the water will be confined to one compartment, keeping the ship afloat. The Herald’s design had an open car deck with no dividers, allowing vehicles to drive in and out easily, but this design allowed water to flood the car deck. As the ferry turned, the water on the car deck moved to one side and the vessel capsized. One hundred and ninety three passengers and crew were killed.
In this accident, those making decisions about vessel design, harbor design, cargo management, passenger management, traffic scheduling, and vessel operation were unaware of the impact of their decisions on the others and the overall impact on the process leading to the ferry accident.
fonte: Applying systems thinking to analyze and learn from events, Nancy Leveson
Entre as falhas operacionais, falhas na integração dos diversos componentes neste sistema complexo e os desafios em manter um padrão de qualidade condizente com o risco da operação, nós vemos que o acidente já havia dado sinais de que poderia acontecer em algumas outras instâncias, esses sinais foram ignorados ou não foram investigados e remediados devidamente, até o dia em que as condições desfavoráveis pegaram toda a tripulação desprevenida, quase como uma tempestade perfeita.
Sabendo disso, a FAA, assim como outras agências em diversas outras indústrias elaboram processos e mecanismos para garantir que casos de quase acidentes sejam investigados para garantir a qualidade e segurança geral de um sistema complexo como estes.
Com esta mentalidade é possível mitigar diversos problemas, ainda pequenos, que poderiam levar a problemas e acidentes maiores e mais graves. Esse é um dos mecanismos e modelos mentais que faz com que a indústria de aviação seja uma das mais seguras que existe.
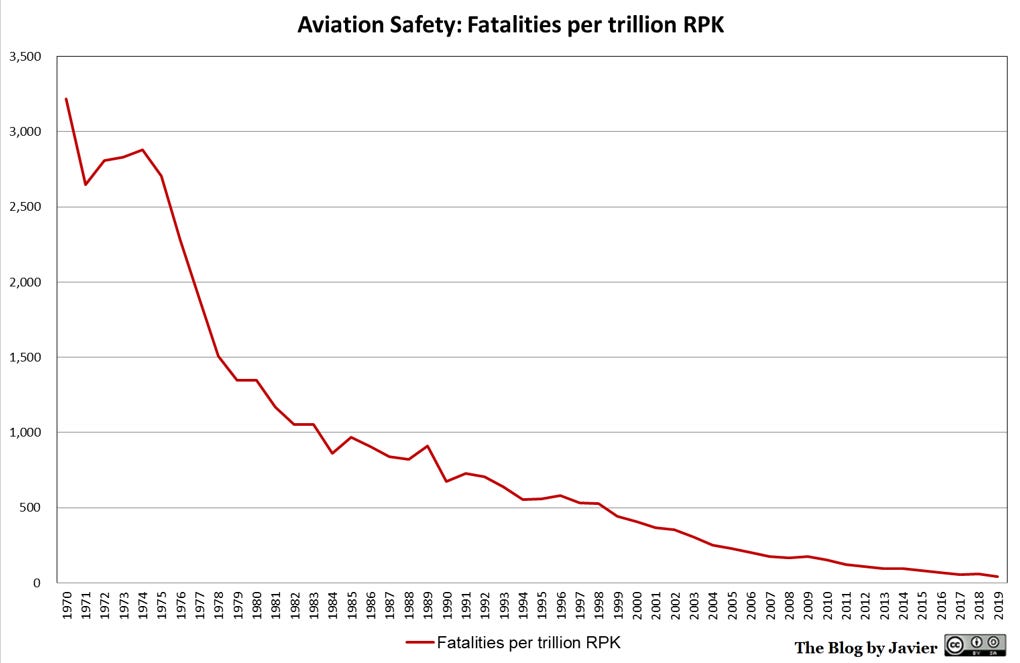
Fatalidades por revenue passengers kilometers. Fonte: Aviation Safety ( wikipedia )
As implicações de “near misses” para produtos, delivery e operação
Vamos considerar agora um e-commerce onde o usuário coloca produtos de sua escolha em um carrinho, faz o seu login/cadastro e finaliza a sua compra com algum método de pagamento.
Sabemos por diversas pesquisas que a tolerância de um usuário para os tempos de espera após clicar em um botão na interface do usuário e receber um feedback sobre a sua ação é pequena e influencia diretamente na conversão ( ou não ) em um e-commerce:
0.1 segundos: percepção do usuário de que recebeu uma resposta instantânea.
até 1.0 segundo: tempo máximo para o usuário manter o seu pensamento sem interrupções focado apenas naquela atividade/ação que está executando.
até 10 segundos: tempo máximo para manter a atenção do usuário. Para tempos maiores do que esse o usuário vai querer fazer outras atividades em paralelo ou provavelmente desistir da ação sendo executada.
Se analisarmos os tempos médios de espera de um usuário ao clicar em um botão “finalizar pedido” em um e-commerce na forma de um histograma, possivelmente veremos uma distribuição da seguinte forma:
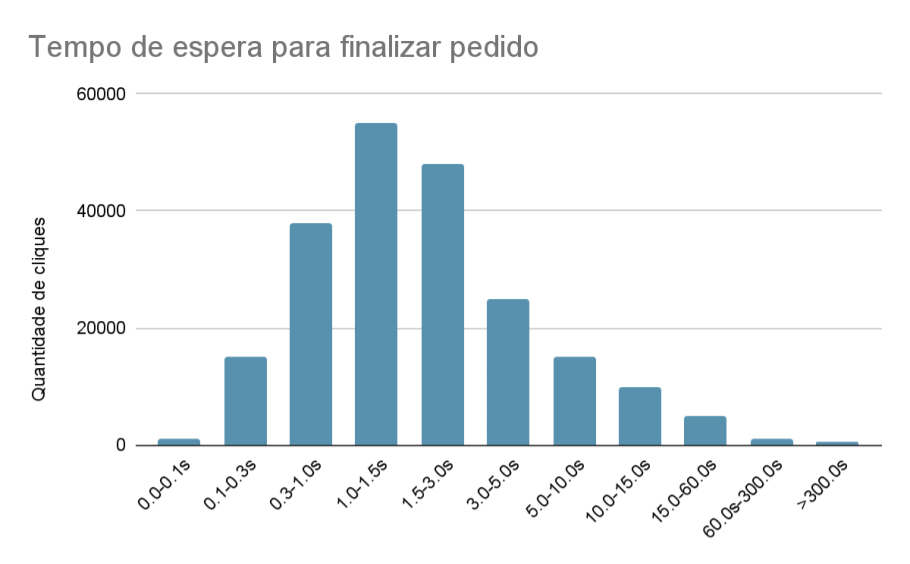
Acima: o gráfico mostra a quantidade de cliques em “finalizar pedido” (eixo-y) distribuído pelo seu tempo de resposta (eixo-x) em uma faixa, de 0.0 até 0.1 segundos, de 0.1 até 0.3 segundos e assim por diante.
Ou seja, de acordo com este exemplo, ao clicar em “finalizar compra” a grande maioria dos usuários experimenta tempos de espera razoáveis entre 0.0 e 1.5 segundos para receber um feedback sobre a sua ação.
No entanto, se repararmos, existem usuários que experimentam tempos absurdos de espera, muitas vezes da ordem de 15 segundos ou mais, e uma pequena quantidade acaba experimentando tempos maiores ainda ( > 300 segundos ). Apesar de ser um grupo pequeno, se adotarmos a mentalidade de near misses da FAA podemos descobrir insights interessantes sobre os pontos de stress e falha do nosso sistema.
O que causou esses resultados extremos na nossa distribuição? Quais foram as conjunturas que levaram até este resultado? Essa conjuntura evidencia algum cenário de fragilidade do sistema em questão?
Os motivos hipotéticos aqui poderiam ser desde usuários que tentaram fechar pedido durante uma janela de deploy e por isso o tempo alto de espera, até coisas mais mundanas, como usuários que apresentam algum comportamento de borda, por exemplo, fazendo pagamentos com métodos que sejam menos comuns e que possivelmente sejam menos testados, ou ainda um excesso de demanda e acesso que sobrecarregou o sistema.
Essa investigação rigorosa pode evidenciar possíveis melhorias no e-commerce como um todo gerando insights sobre como podemos diminuir o impacto negativo das janelas de deploy ou ainda zerar o down time utilizando boas práticas de engenharia. Para o caso do método de pagamento incomum, conseguimos avaliar a necessidade de mantê-lo? Ou se precisarmos mantê-lo, testá-lo com mais afinco para encontrar e resolver os seus gargalos?
A mesma análise pode ser feita a cerca de itens em um backlog de uma equipe, se olharmos o leadtime dos itens em desenvolvimento, possivelmente vamos encontrar uma curva com a seguinte distribuição:

fonte: Releasing hidden capacity at Heineken, John Carrier
Os itens poderiam ser categorizados da seguinte forma: Os que estão pintados de verde na curva ( número 4 ) são os itens que ficaram menos tempo até serem entregues, normalmente são os itens que o CEO pediu para ontem e que furaram a fila para terem o máximo de urgência, ou talvez sejam itens mais fáceis e rápidos de serem implementados e entregues.
A grande maioria dos itens estão sob a cor azul ( número 3 ), esse é o tempo médio que um item demora até ser entregue, normalmente é o que acontece com itens neste backlog: alguns são um pouco mais rápidos, outros mais devagar, mas na média a grande maioria tem esse tempo até ser finalizado.
Os de cor laranja ( número 2 ) já exemplificam itens que demoraram mais do que de costume, embora talvez ainda estejam dentro de um patamar aceitável, eles já começam a evidenciar os limites de capacidade de entrega naquele contexto.
Os itens de cor vermelha ( número 1 ) são raros mas acontecem e quando acontecem costumam ser um desastre: o seu tempo até ser finalizado é tão grande que provavelmente gera problemas com as partes interessadas na sua resolução ou talvez, e pior, quando pronto, eles provavelmente já não atendam mais os objetivos de negócio e a necessidade do usuário.
Itens do último tipo por serem pouco frequentes normalmente são ignorados, afinal de contas não é todo dia que um avião tenta pousar por cima de outro em um aeroporto. No entanto, eles costumam ser os itens que mais evidenciam pontos de falha de um sistema, que se examinados, investigados e mitigados, podem apresentar ganhos de performance e qualidade que evitarão problemas maiores no futuro quando o sistema for estressado até esse ponto, talvez sem uma contingência.
Um último exemplo pode ser o processo de onboarding de um novo funcionário em uma empresa de tecnologia: para a maioria dos casos, os funcionários recebem as suas máquinas para executar o seu trabalho no dia ou antes de começarem, são bem recebidos pelos seus gestores e com calma e de maneira deliberada aprendem durante um período de tempo sobre como a empresa funciona e as suas atribuições e responsabilidades como funcionário.
Essa provavelmente é a jornada da grande maioria de funcionários em uma empresa hipotética, porém se analisarmos casos onde essa experiência degradou podemos identificar diversos pontos de risco e melhoria de performance na corporação: a máquina do funcionário não chegou a tempo? Será que temos um gargalo no processo de suporte ou de compras? A notificação sobre a data de entrada do funcionário chegou muito em cima da hora para o departamento pessoal? Será que temos alguma impedância na interação entre o RH, gestores e o DP?
Identificar e mitigar essas situações requerem um processo sistematizado e uma disciplina de execução e revisão de incidentes e near misses que é essencial para levar uma corporação para a excelência.
Disciplina, limites e revisão dos incidentes
Ao investigar de maneira sistemática os incidentes de cauda ou os que quase caracterizaram um acidente, a equipe envolvida é necessariamente forçada a olhar o sistema como um todo e fazer uma análise sobre as causas raízes, suas relações de causa e efeito e as consequências que acabaram por levar até aquele caso.
Uma equipe pode estabelecer limites claros para o que constitui um incidente e ir gradualmente aumentando o patamar deste limite para estimular o comportamento do sistema na direção desejada, de maneira similar ao incentivos e comportamentos que exploramos em artigos anteriores:

Outro aspecto importante é a disciplina de revisar os incidentes de forma a chegar a sua causa raiz, o entendimento das relações de causa e efeito e mais importante do que isso elucidar aspectos do sistema em questão que podem ser frágeis em uma certa condição de parâmetros e fatores.
Igualmente importante é a prática de revisar os quase incidentes e obter aprendizado sobre as suas causas e as condições em que ocorreu. Caso o sistema se encontre sob stress ou acima da sua capacidade, existe uma grande possibilidade de que esses quase acidentes se tornem acidentes de fato.
Eu acredito que o mercado de tecnologia e produtos/serviços digitais tem muito a aprender e evoluir em relação a práticas que já são amplamente conhecidas e difundidas em outras indústrias que possuem um track record muito melhor do que a nossa.