
Uma visão sistêmica para o desenvolvimento de produtos - Parte 3
Uma visão sistêmica para o desenvolvimento de produtos - Parte 3
Gerindo um ativo digital

O objetivo desse artigo é ajudar o head de uma prática a planejar e simular cenários viáveis para lidar com as complexidades de gerir um capability que é composto, entre outras coisas, por um produto digital.
De maneira quantitativa, queremos explorar algumas perguntas, por exemplo: quais são as abordagens de maior ou menor sucesso na hora de extrair mais performance a partir da entrega de novas funcionalidades ou melhorias? Como sair de um ciclo de fire fighting para um ritmo sustentável de trabalho? Será que o investimento sistemático em melhoria realmente se paga no final? Em que horizonte de tempo?
Modelo conceitual para visualizar o fluxo de valor de uma equipe trabalhando em um produto digital
Considerando uma visão de estoque e fluxo para o desenvolvimento de um ativo digital ( por exemplo, um canal mobile de uma empresa e os componentes necessários para suportá-lo ), podemos visualizar a sua dinâmica de comportamento com o modelo abaixo, onde temos uma abstração sobre as relações das diversas filas ( estoques ) e os fluxos entre cada uma delas:
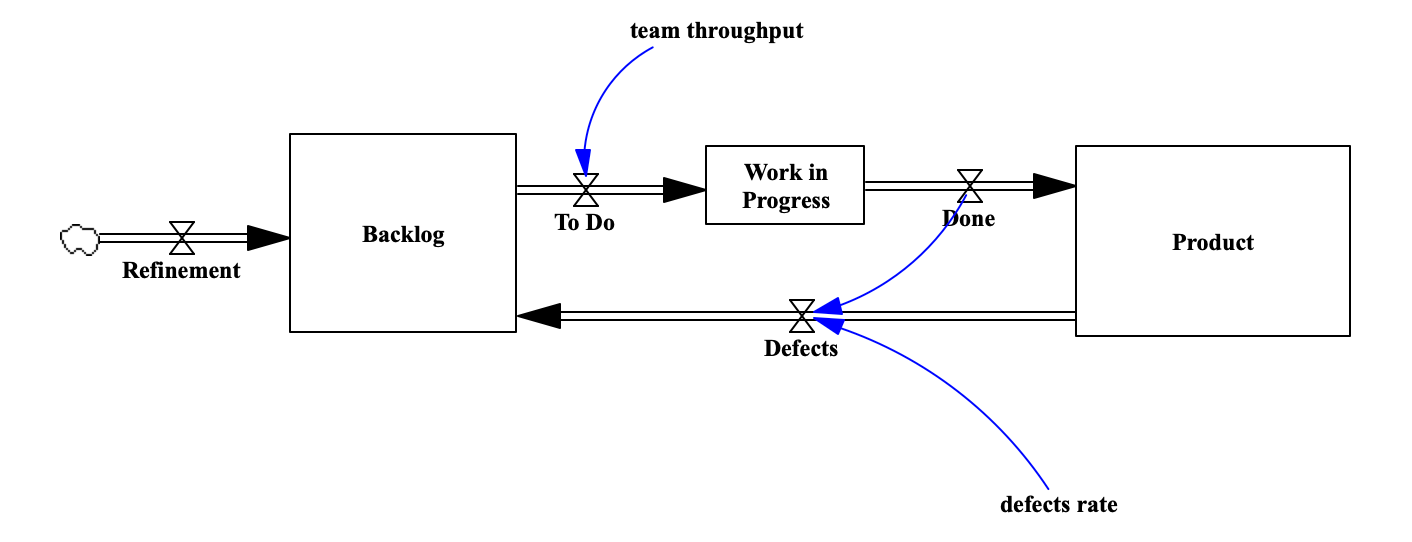
Por exemplo, fluxo de itens em refinamento são adicionados ( se acumulam ) na lista de itens do backlog, que eventualmente são puxados ( fluxo de itens em to do ) se tornando o estoque de itens em desenvolvimento ( work in progress ). Esse estoque de itens em WIP é eventualmente finalizado, gerando o fluxo de itens finalizados ( done ), que enfim compõe o que chamamos de produto ( definido aqui como o acumulo de todos as linhas de código, atividades, processos, sistemas, procedimentos e práticas, integrações, configurações que compõem o produto e que foram envolvidos nas atividades executadas ).
Esse estoque que estamos abstraindo como o produto, eventualmente possui defeitos (sejam eles por má construção, aspectos funcionais e não funcionais não aderentes, ou ainda desatualização do mesmo ), esses defeitos, que acontecem em uma taxa ( defects rate ), diminuindo o estoque do mesmo, afetando a sua performance. Quando um defeito é descoberto, normalmente um item é gerado de volta para o backlog para que o defeito seja tratado pelo time.
Esse modelo conceitual usando a abstração de estoque e fluxo, permite uma visão sistêmica bastante vantajosa para avaliarmos as boas e más práticas ao gerir um produto digital ao longo do tempo.
Throughput do time e acumulo de backlog
No diagrama acima, vemos a relação entre a quantidade de itens que saem do estoque backlog para o estoque work in progress. Esse fluxo é determinado pelo throughput do time. Em outras palavras, o fluxo de itens que efetivamente saem de backlog para work in progress leva em consideração a capacidade de vazão ( throughput ) daquele grupo de trabalho.
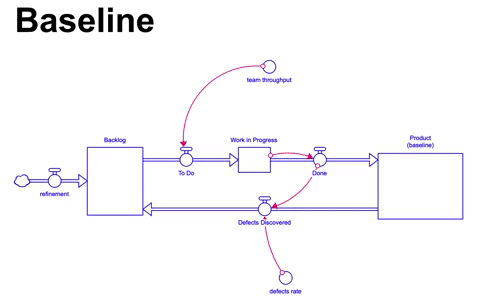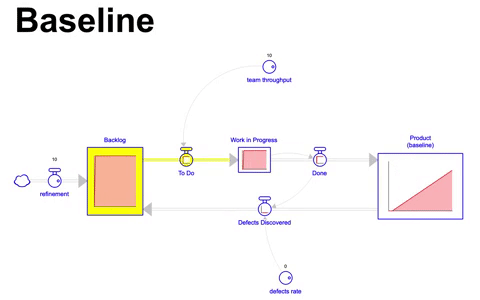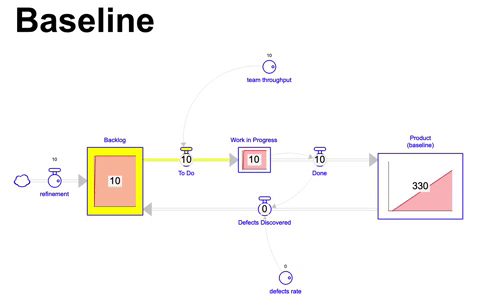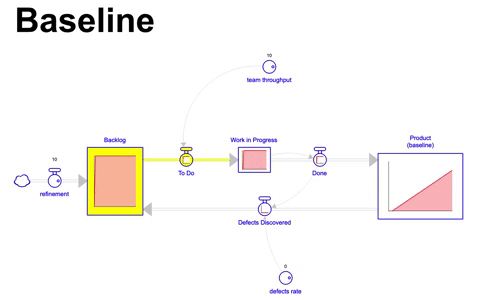
Se o time possui um throughput de 10 itens por mês e a quantidade de itens entrando no backlog ( refinement ) é equivalente a esse throughput ( ou seja, a taxa de entrada ou arrival rate de itens no backlog é de 10 itens por mês também ) durante o período simulado de 36 meses, o sistema se encontraria em seu potencial máximo se a taxa de defeito for 0% ( o cenário onde tudo que é construído não possui defeito ) entregando 330 itens que compõem o produto, conforme abaixo:
No entanto, raramente nos encontramos com uma situação onde a taxa de novos itens no backlog é exatamente igual ao throughput do time, o cenário mais usual é que a habilidade de gerar novas ideias e oportunidades é consideravelmente maior do que a capacidade disponível para construir e entregá-las.
Simulando um cenário onde a taxa de itens adicionados ao backlog é 20% maior do que throughput do time temos o seguinte comportamento do sistema:
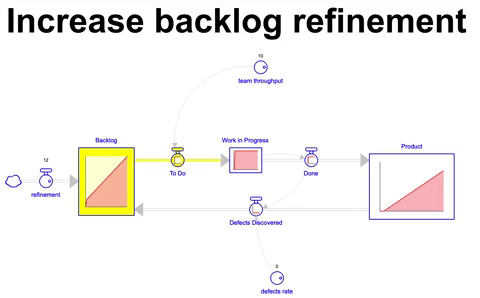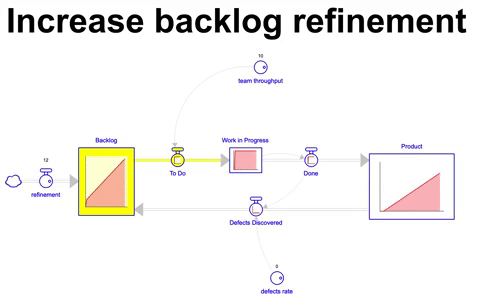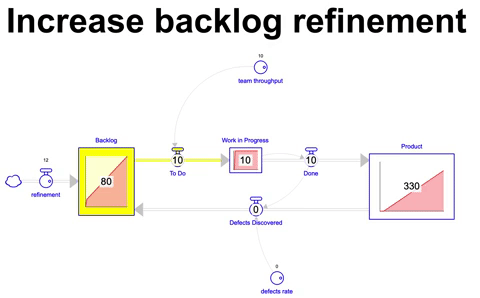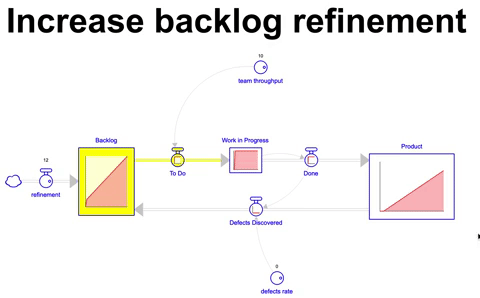
Adicionando 12 itens por mês durante 36 meses ao backlog de um time que possui um throughput de 10 itens por mês, a quantidade final de itens que acaba sendo construída é obviamente a mesma que a anterior ( 330 nesse exemplo ), no entanto o estoque de itens no backlog é de 80 itens ao final de 36 meses. Considerando o throughput do time de 10 itens por mês, demoraríamos 8 meses para finalizar todo esse inventário no backlog caso nenhum item adicional fosse criado nesse interim. Um custo de oportunidade considerável para qualquer empresa.
Claramente apenas adicionar itens ao backlog a despeito do throughput do time é uma estratégia pouco otimizada, no final, o que você encontra é simplesmente um estoque de itens por fazer que continua crescendo.
Além disso, a simulação acima não considera os efeitos mais amplos em um time nessa condição, que observa um conjunto enorme de itens por fazer, sem a capacidade de throughput, causando a sensação de sobrecarga e ansiedade, aumento da taxa de defeitos e outros males que mencionamos nos artigos anteriores.
No entanto, ambas as simulações que fizemos acima são irreais, pois assumem um cenário onde tudo o que é construído não possui nenhum defeito.
Voltando ao nosso cenário baseline e adicionando um fator onde 5% de tudo o que é construído possui defeito, terminamos com um estoque do produto menor, e vemos que o acumulo é ligeiramente diferente do que o projetado no primeiro cenário:
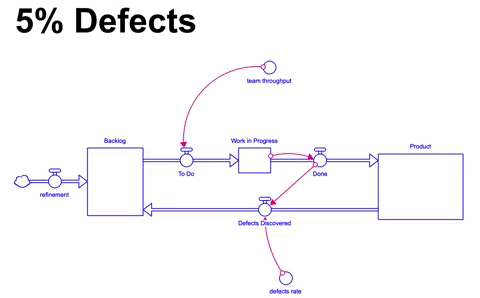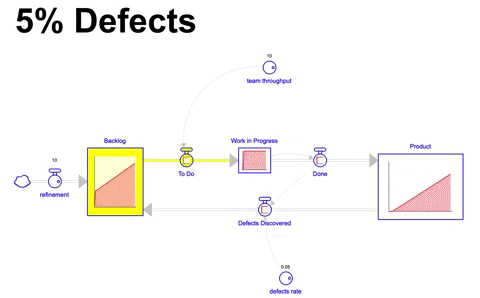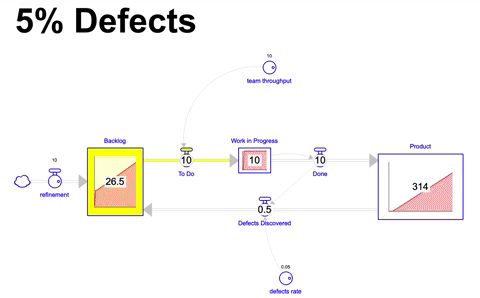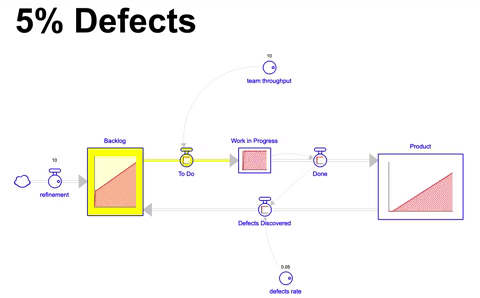
Nesse cenário, bem mais realista, 5% do que fica pronto em um mês apresenta defeito, e por conta disso, volta para o backlog de itens para ser trabalhado. Após 36 meses de simulação terminamos com 314 itens incorporados ao produto ( 5% a menos do que o estado ideal de 330 ), no entanto, temos também um backlog de 26.5 itens ao final.
Em um cenário mais realista ainda, a taxa de defeitos não ficaria constante por muito tempo, simulando então uma taxa de defeitos de 5% que aumenta ao longo de 18 meses até 25% e se mantem nesse patamar pelos próximos 18 meses, vemos o seguinte comportamento:
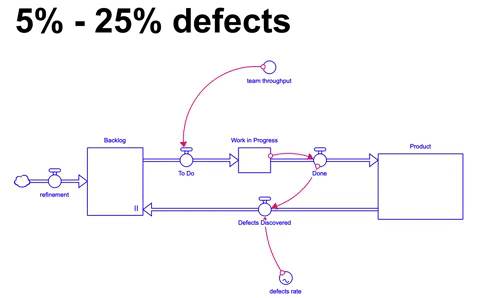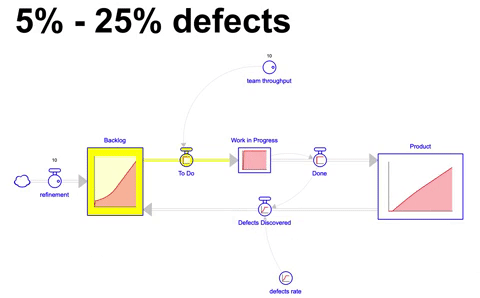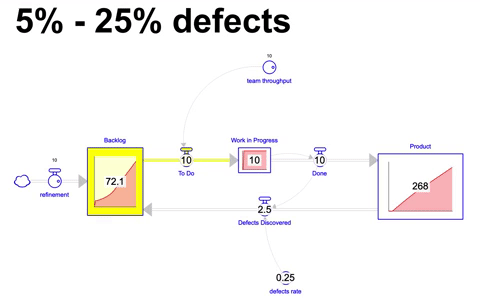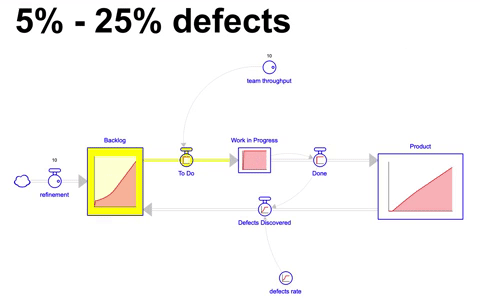
Temos o pior resultado até o momento: 268 itens incorporados ao produto, um backlog ao final dos 36 meses de 72 itens, o que demoraria em torno de 7 a 12 meses para serem completados dependendo da taxa de defeitos durante esse período.
Equipe de bombeiros e “stop the line”
Uma tática comumente adotada em cenários como os últimos que exploramos acima é a dedicação de uma equipe de bombeiros para apagar incêndios e remediar os problemas em produção, na operação ou na construção dos itens.
Nesse cenário o nosso modelo conceitual é ligeiramente alterado: teremos duas equipes com throughputs distintos atacando simultaneamente backlogs distintos de atividades ( uma construindo novas funcionalidades e outra resolvendo problemas urgentes e defeitos, normalmente no ambiente produtivo ).

Simulando o cenário onde, uma equipe de bombeiros possui um throughput equivalente a 10% do throughput da equipe que continua trabalhando em novos itens de backlog, e a taxa de defeitos se comportando como no cenário anterior ( indo de 5% até 25% em 18 meses e se mantendo nesse patamar por mais 18 meses ), ao final de 36 meses de execução nos encontramos na seguinte situação:
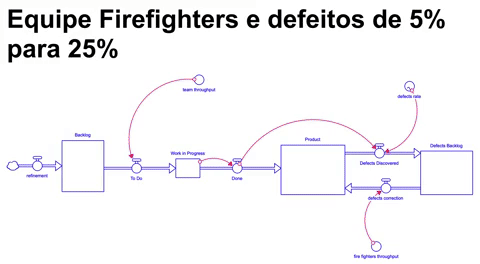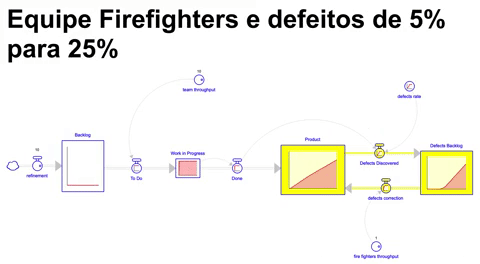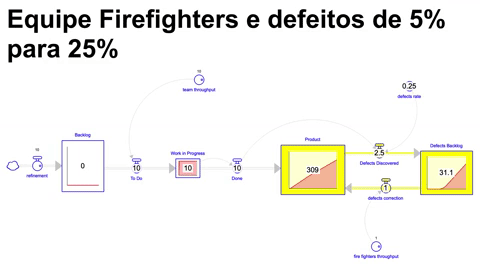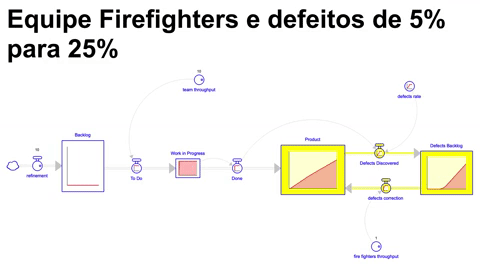
Reparem que ao final conseguimos chegar em um patamar considerável de itens incorporados ao produto, no entanto, o backlog de problemas encontrados aumenta em uma velocidade bastante acelerada, indicando que apesar de mantermos o nível de entrega, vamos acumulando um conjunto de defeitos e problemas a serem sanados dentro desse produto que inevitavelmente vai gerar grandes desafios para a operação, evidenciando uma ineficiência: emprega-se mais esforço para manter-se em um patamar por conta dos defeitos no que é produzido.
Além disso, a abordagem de bombeiros ( assim como na vida real, ao lidar com incêndios no mundo físico ) deve ser usada em casos de emergências, e contar sempre com a capacidade de bombeiros entrando em missões críticas para resolver o problema no curto prazo não é algo sustentável no longo prazo.
Essa transferência do fardo ao destinar a resolução de problemas para uma equipe diferente da que os gerou acaba, causando problemas graves de responsabilidades e erosão de padrões de qualidade, o que inevitavelmente onera a cultura e a performance geral da empresa.
Uma abordagem alternativa a de bombeiros é a que chamamos de stop the line, onde abruptamente se interrompe a linha de desenvolvimento ( ou produção ) para que os problemas sejam resolvidos, essencialmente paralisando integral ou parcialmente a operação.
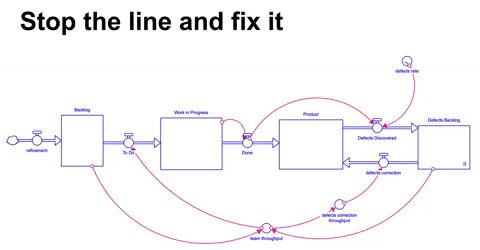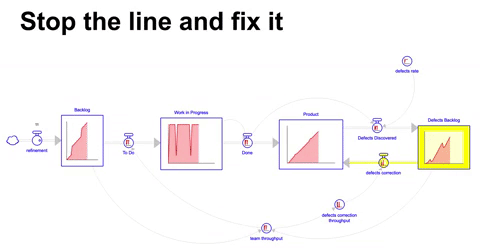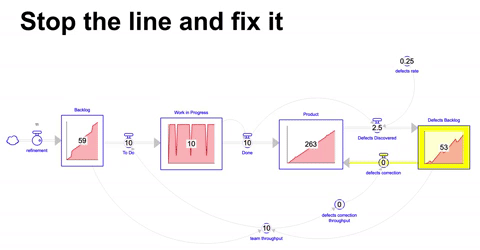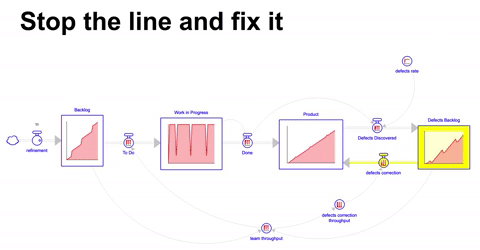
Neste cenário drástico, o throughput do mesmo time é dividido entre o desenvolvimento de novas funcionalidades e eventualmente quando o acumulo de problemas e defeitos descobertos passa de um patamar em relação ao backlog de atividades ( no caso simulado ( backlog de defeitos / backlog ) > 1 ) diminuímos a vazão no desenvolvimento de novas funcionalidades e focamos a maior parte do throughput do time na correção de bugs e defeitos.
Diferentemente do tradicional andon ou pull the chord do Toyota Production System, a abordagem aqui não é dar autonomia para os funcionários pararem a linha quando virem um problema, mas sim parar a linha para corrigir uma parte dos defeitos em mão quando passamos de um patamar de problemas acumulados.
Esses solavancos na operação tendem a ser traumáticos, e eventos onde isso acontece constantemente podem indicar uma operação que está operando no limite ( ou mesmo acima ) da sua capacidade.
Os problemas ocultos
Roger Bohn em seu artigo “Stop Fighting Fires” publicado na Harvard Business Review em julho do ano 2000 abordou o tema de fire fighting e descreveu diversas táticas e estratégias para sair de uma cultura de apagar incêndio para uma cultura de aprendizado.
Um dos temas mais importantes citados por ele é a predominância de problemas negligenciados ou que não sejam resolvidos em sua causa raiz mas sim apenas em alguns dos seus sintomas.
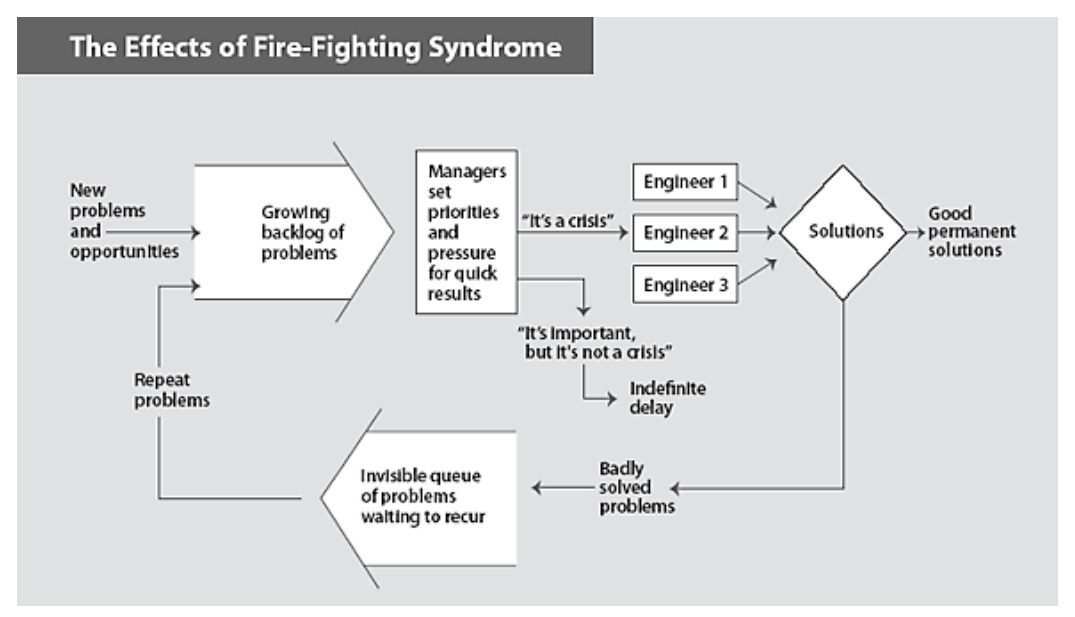
fonte: Stop Fighting Fires, Roger Bohn - HBR
Esse backlog invisível ( e por conta disso, não gerenciado ) de problemas se acumula ao longo do tempo podendo levar a situações catastróficas. Para evitar esse cenário é importante que se instaure um mindset de prevenção de problemas ( e não apenas de correção reativa de problemas ), algumas das formas citadas para se atingir esse ponto são:
Resolva classes de problemas e não problemas individuais: quando confrontado com um problema, examine a natureza do problema e tente determinar se ele pertence a um grupo maior cujos sintomas são sentido em diversos pontos, por exemplo, falta de qualidade na etapa de validação final de um produto pode ser um sintoma de um ritmo/carga de trabalho insustentável, o que também pode estar causando o problema de turn-over de membros do time e acúmulo de horas extras, assim como erros por fadiga e stress.
Não tolere quick fixes e workarounds: resista a tentação de resolver problemas dessa maneira, apesar de útil no curto prazo, eles tendem a transformar o problema mais insustentável no médio e longo prazo. Procure soluções que afetem a causa raiz dos problemas.
Não recompense o comportamento heróico e de bombeiro: em muitas corporações, o comportamento heróico onde problemas são resolvidos de forma insustentável após longos turnos de trabalho executados consistentemente pelo mesmo grupo de pessoas, é visto como algo culturalmente aceitável e enaltecido. Essa indução de comportamento no longo prazo vai gerar um ambiente insustentável, de baixa performance, baixo aprendizado e resultados cada vez menores.
Melhoria contínua e ritmo sustentável de trabalho
Voltando ao capability trap descrito no artigo anterior, vamos analisar agora uma abordagem na linha do work smarter em vez de atuações mais táticas do tipo work harder para resolver os problemas de performance e entrega simulados aqui.
Nessa simulação, consideramos um time com um throughput de 10 itens por mês assim como a quantidade de 10 itens refinados por mês. No entanto, desde o inicio o throughput do time não é integralmente dedicado para a construção de novas features: 20% do mesmo é dedicado a melhorias de maneira contínua, provendo tempo para que o time sistematicamente mantenha, evolua e melhore esse ativo.
O aspecto positivo dessa abordagem é que dedicamos tempo e esforço para melhorias, já o aspecto negativo é que removemos tempo e esforço para a construção de novas funcionalidades.
Para transformar a simulação em algo mais real, adicionamos uma taxa de defeitos que vai de 5% do que é construído para 25% em 6 meses, e depois se mantem nesse patamar. Ou seja, problemas estão acumulando e o throughput de novas funcionalidades é menor pois dedicamos parte dele para melhorias.
Assumindo que após alguns meses dedicando tempo e esforço para melhorias, a taxa de defeitos deveria diminuir, assim como após algum tempo o throughput do time deveria subir devido ao acúmulo de melhorias aplicadas dando ganhos de produtividade, teríamos então o seguinte resultado:
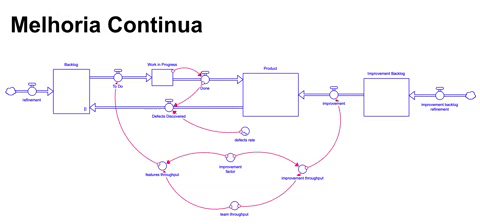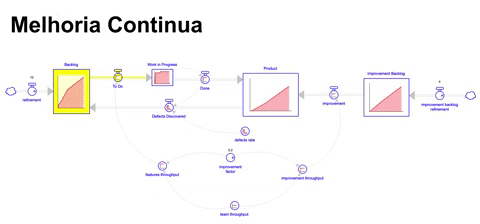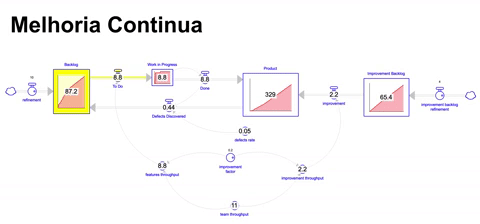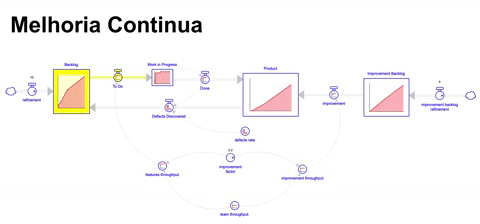
Apesar de ser um dos melhores resultados dada a nossa simulação ( 329 itens acumulados no produto ao longo de 36 meses ), ainda sim terminamos com um backlog bastante grande ( 87 itens ), que demoraria aproximadamente 8 meses para o time escoar.
Uma abordagem que podemos seguir para limitar o acumulo de backlog, seria implementar um sistema puxado, onde a quantidade de itens refinados é proporcional ao throughput dedicado para novas features, como no exemplo abaixo:

Neste cenário, terminamos com um backlog de 36 itens (3 a 5 meses de previsibilidade de itens por fazer ) e um equilíbrio sustentável entre novas funcionalidades e melhorias, causando um aumento de throughput e redução da taxa de defeitos.
A última abordagem que vamos explorar é um cenário bastante próximo do mundo real: uma operação precisa continuar construindo novos itens e gerando resultado assim como também deve continuar dedicando tempo de maneira sistemática para melhoria contínua, conforme vimos na simulação anterior. Para sinalizar que temos capacidade para executar um novo lote de trabalho, utilizamos um sistema puxado.
Adicionalmente, no mundo real existem problemas de curto prazo causados pelo defeitos que necessitam de atenção imediata. Para endereçar esses problemas podemos lançar mão de capacidade adicional e temporária para permitir o combate em múltiplas frentes: novas funcionalidades, melhoria contínua e o apagar de incêndio, simulamos então a combinação dessas três táticas, gerando o nosso melhor resultado até agora.
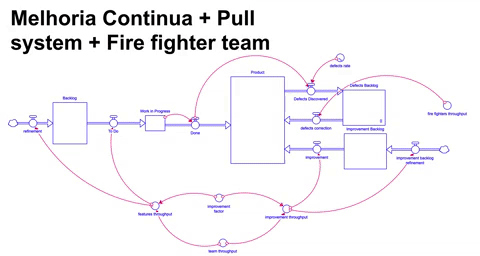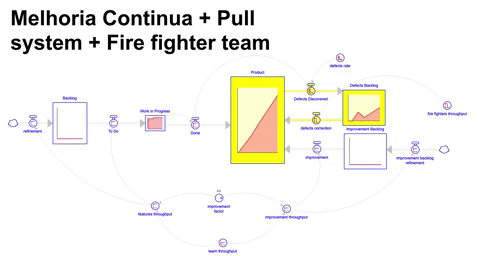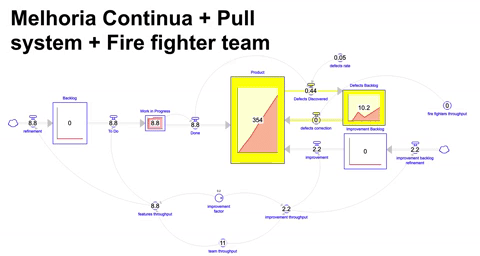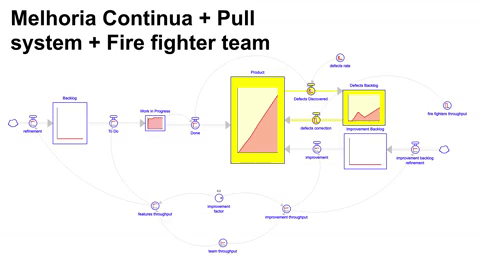
Obviamente a abordagem acima requer que duas restrições sejam “afrouxadas”: custo/investimento, assim como tempo/paciência. Aumentamos a capacidade disponível para conseguir simultaneamente atender as necessidades de novas funcionalidades, melhoria contínua e apagar de incêndio.
Neste cenário temos um resultado pior ( worse before better ) no curto prazo se comparado com abordagens anteriores, no entanto, com o passar do tempo e com a diminuição de defeitos e aumento de throughput a partir das melhorias terminamos por entregar mais no médio/longo prazo.
Vale ressaltar que um efeito do aumento de capacidade é o aumento na complexidade de coordenação e interação dos diferentes ( e agora maiores ) grupos de trabalho. Neste cenário não é difícil se encontrar em um estado congestionado onde a tomada de decisão e a velocidade da empresa em atingir um objetivo é retardada devido a dificuldade de coordenação. O outro efeito é que muitas vezes podemos simplesmente não ter tempo hábil ou a adesão da liderança para esperar que os investimentos eventualmente aumentem a performance.
O mundo real não é um modelo
O ato de gerenciar, quando analisado por uma perspectiva sistêmica, pode ser definido como o ato de equilibrar restrições em um sistema dinâmico complexo que muitas vezes trabalham em direções opostas e que se balanceiam: temos que ter a performance X, mas não podemos estourar o budget Y, precisamos aumentar a qualidade para o patamar Z, mas precisamos fazer dentro da data W, precisamos encantar o cliente mas precisamos otimizar os nossos custos e assim por diante.
Os modelos acima, ajudam a descrever cenários com o intuito de acelerar o nosso aprendizado ( que poderia potencialmente demorar 36 meses para acontecer ) e ajudar no nosso processo de tomada de decisão em um ambiente dinâmico e complexo.
No entanto, como todo e qualquer modelo, ele é incapaz de capturar todas as complexidades do mundo real ( por isso chamamos ele de modelo e não de mundo real ), assim como já dizia um dos expoentes da estatística no século 20:
“All models are wrong, but some are useful”
George Box
O que é realmente importante nesta discussão ao longo dos últimos artigos é como conseguimos acelerar e aumentar o aprendizado organizacional em relação a forma como atuamos dentro das nossas empresas.
As armadilhas em que podemos cair por ignorarmos os atrasos ( delays ) entre as relações de causa e efeito de uma ação, a inobservância de ciclos de feedback que afetam e são afetados a partir das interações dos agentes desse sistema, e a dificuldade de visualizarmos as relações entre os estoques e os fluxos que compõem e descrevem como esse sistema é estruturado fazem com que operar e intervir nele como um gestor seja uma tarefa arriscada.
No último artigo da série, vamos falar sobre programas de melhorias e como evitar que um barco afunde, e caso você, infelizmente se encontre em uma situação dessas como você poderia salvar um barco em movimento com diversos furos.
E por último vamos analisar um pouco a estruturas externas à empresa que ajudam a pautar a agenda de curto ou médio/longo prazo da liderança, por exemplo, o mercado de capitais, expectativas de retorno para os acionistas/investidores e outras dinâmicas que invariavelmente determinam como será a performance de uma empresa no curto, médio e longo prazo.